Speeding up HX711 Library
-
Hello Everybody,
I’m using a library from github (https://github.com/geda/hx711-lopy) to read values from a HX711 board that’s connected to a wheat stone bridge pressure sensor on my WiPy 3.0.
However for my application i would like to read values at high speed. I’m currently getting about 14 ms per read value.
The delay is in the driver/library not my piece of code (than its 0-1 ms), but i’m not sure why or what is taking so long.I’m a novice so i don’t quite understand what the author of the library is doing at every step.
I’ve tried/considered:
-Increasing the speed using @micropython.native to emit native CPU opcodes however that’s not yet implemented in the Pycom fork.
-Increasing the Clockspeed to 240 Mhz however that required re-compiling the firmware and that’s a little above my capabilities right now. (maybe still worth the try)
-Reducing the averaging done in the library at certain steps however with no succes.I’ve read floating point numbers take up time is this true?
Diver code:
from machine import Pin class HX711: def __init__(self, dout, pd_sck, gain=128): self.pSCK = Pin(pd_sck , mode=Pin.OUT) self.pOUT = Pin(dout, mode=Pin.IN, pull=Pin.PULL_DOWN) self.GAIN = 0 self.OFFSET = 0 self.SCALE = 1 self.lastVal = 0 self.allTrue = False self.set_gain(gain); def createBoolList(size=8): ret = [] for i in range(8): ret.append(False) return ret def is_ready(self): return self.pOUT() == 0 def set_gain(self, gain): if gain is 128: self.GAIN = 1 elif gain is 64: self.GAIN = 3 elif gain is 32: self.GAIN = 2 self.pSCK.value(False) self.read() print('Gain setted') def read(self): dataBits = [self.createBoolList(), self.createBoolList(), self.createBoolList()] while not self.is_ready(): pass for j in range(2, -1, -1): for i in range(7, -1, -1): self.pSCK.value(True) dataBits[j][i] = self.pOUT() self.pSCK.value(False) #set channel and gain factor for next reading for i in range(self.GAIN): self.pSCK.value(True) self.pSCK.value(False) #check for all 1 if all(item == True for item in dataBits[0]): #print('all true') self.allTrue=True return self.lastVal self.allTrue=False readbits = "" for j in range(2, -1, -1): for i in range(7, -1, -1): if dataBits[j][i] == True: readbits= readbits +'1' else: readbits= readbits+'0' self.lastVal = int(readbits, 2) return self.lastVal def read_average(self, times=3): sum = 0 effectiveTimes = 0 readed = 0 for i in range(times): readed = self.read() if self.allTrue == False: sum += readed effectiveTimes+=1 if effectiveTimes == 0: return 0 return sum / effectiveTimes def get_value(self, times=3): return self.read_average(times)# - self.OFFSET def get_units(self, times=3): return self.get_value(times) / self.SCALE def tare(self, times=15): sum = self.read_average(times) self.set_offset(sum) def set_scale(self, scale): self.SCALE = scale def set_offset(self, offset): self.OFFSET = offset def power_down(self): self.pSCK.value(False) self.pSCK.value(True) def power_up(self): self.pSCK.value(False)Would appreciate any pointers.
Thanks again!p.s. see the hidden feature requests!
-
@jimpower The load sensor combinator shown combines four half bridge load cells in a way, that it looks like one full bridge load cell. It is a pure passive board simplifying the wiring. The output has to be fed into a load cell amplifier and digitizer.
-
@robert-hh would it be better to use something like this Load Sensor Combinator with the expansion board would I still require the Load Cell Amplifier
-
@jimpower Yes and no. Easy, if you spend 2 IO ports for each load cell. Data is input only, so you can use the analog input only for that. Then you can run all load cells in any mode.
Without changing the code, and if you run all devices in the same mode and have no speed demands, you can also share the clock gate with all devices, and read them one after the other.
By changing the bit bang code, you could read all 4 cells in one cycle within the read() method, by sharing the clock signal and just splitting up the data lines to four GPIO ports. After the pulse up/down cycle the code has plenty of time to read the state of all four load cells. The total time for reading would not be increased a lot.
-
@robert-hh could it be possible to connect 4 load cells up with this library?
-
@epstein I made a few longer term measurement with the HX711 and a load cell. That one has a pretty low output voltage, so the output value was just at about 4% of the HX711 range. The results are in the table below. During that test over a set of about 5 million samples taken, not value was seen which was completely out of range. So the error state, which the geda implementation tries to avoid, was most likely caused by power down events. The lowpass filter is a simple 1 level filter of the kind:
value_out = tau * new_value + (1.0 - tau)*value_out
where the start value of value_out is either or some other reasonable value, and tau is the time constant in the range 0-1.0.
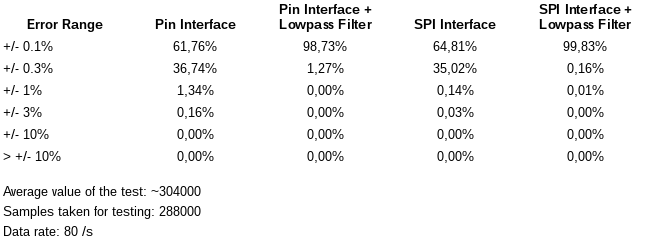
-
@epstein I got my HX711 today and verified the code. The optimized variant is in a simple loop effectively not faster than the slow one, since the slow part of the code happens in the time frame, when the HX711 is anyhow not ready for a new reading.
But I could verify, that the reason for a major slow-down was the coding of the read method, in that during the high cycle of the HX711 clock IRQ is not disabled. In that case, it may happen that the high cycle of the clock is longer than 60 µs, and then the HX711 powers down, and needs400ms to get back to life. Even worse, this power cycle deletes the setting for gain and channel. The optimized code does not have this bug, and could also be simplified. Here is the code:from machine import Pin, enable_irq, disable_irq class HX711: def __init__(self, dout, pd_sck, gain=128): self.pSCK = Pin(pd_sck , mode=Pin.OUT) self.pOUT = Pin(dout, mode=Pin.IN, pull=Pin.PULL_DOWN) self.GAIN = 0 self.OFFSET = 1 self.SCALE = 1 self.set_gain(gain); def set_gain(self, gain): if gain is 128: self.GAIN = 1 elif gain is 64: self.GAIN = 3 elif gain is 32: self.GAIN = 2 self.pSCK.value(False) self.read() print('Gain set') def read(self): # wait for the device being ready while self.pOUT() == 1: pass # shift in data, and gain & channel info result = 0 for j in range(24 + self.GAIN): state = disable_irq() self.pSCK(True) self.pSCK(False) enable_irq(state) result = (result << 1) | self.pOUT() # shift back the extra bits result >>= self.GAIN # check sign if result > 0x7fffff: result -= 0x1000000 return result def read_average(self, times=3): sum = 0 for i in range(times): sum += self.read() return sum / times def get_value(self, times=3): return self.read_average(times) - self.OFFSET def get_units(self, times=3): return self.get_value(times) / self.SCALE def tare(self, times=15): sum = self.read_average(times) self.set_offset(sum) def set_scale(self, scale): self.SCALE = scale def set_offset(self, offset): self.OFFSET = offset def power_down(self): self.pSCK.value(False) self.pSCK.value(True) def power_up(self): self.pSCK.value(False)The variant using SPI is working too. It uses MOSI for the HX711 clock and MISO for the HX711 data. The SPI clock signal is not connected. Here is the copy
from machine import Pin, SPI class HX711: def __init__(self, dout, pd_sck, spi_clk, gain=128): self.pSCK = Pin(pd_sck , mode=Pin.OUT) self.pOUT = Pin(dout, mode=Pin.IN, pull=Pin.PULL_DOWN) self.spi = SPI(0, mode=SPI.MASTER, baudrate=1000000, polarity=0, phase=0, pins=(spi_clk, pd_sck, dout)) self.pSCK(0) self.GAIN = 0 self.OFFSET = 0 self.SCALE = 1 self.clock_25 = b'\xaa\xaa\xaa\xaa\xaa\xaa\x80' self.clock_26 = b'\xaa\xaa\xaa\xaa\xaa\xaa\xa0' self.clock_27 = b'\xaa\xaa\xaa\xaa\xaa\xaa\xa8' self.clock = self.clock_25 self.lookup = (b'\x00\x01\x00\x00\x02\x03\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00' b'\x04\x05\x00\x00\x06\x07\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00' b'\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00' b'\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00' b'\x08\x09\x00\x00\x0a\x0b\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00' b'\x0c\x0d\x00\x00\x0e\x0f') self.in_data = bytearray(7) self.set_gain(gain); def set_gain(self, gain): if gain is 128: self.clock = self.clock_25 elif gain is 64: self.clock = self.clock_27 elif gain is 32: self.clock = self.clock_26 self.read() print('Gain set') def read(self): # wait for the device to get ready while self.pOUT() != 0: pass # get the data and set channel and gain self.spi.write_readinto(self.clock, self.in_data) # pack the data into a single value result = 0 for _ in range (6): result = (result << 4) + self.lookup[self.in_data[_] & 0x55] # check sign if result > 0x7fffff: result -= 0x1000000 return result def read_average(self, times=3): sum = 0 for i in range(times): sum += self.read() return sum / times def get_value(self, times=3): return self.read_average(times) - self.OFFSET def get_units(self, times=3): return self.get_value(times) / self.SCALE def tare(self, times=15): sum = self.read_average(times) self.set_offset(sum) def set_scale(self, scale): self.SCALE = scale def set_offset(self, offset): self.OFFSET = offset def power_down(self): self.pSCK.value(False) self.pSCK.value(True) def power_up(self): self.pSCK.value(False)
-
@epstein I used this simple script for telling the speed:
from hx711 import * from utime import ticks_ms, ticks_diff # adapt the Pin names as required hx = HX711( "P10", "P11") def run(loops = 100): start = ticks_ms() for _ in range(loops): hx.read() print("Time per read:", ticks_diff(start, ticks_ms())/loops) run()
-
Hi Robert,
I used this:
while program == 1: pycom.rgbled(0x0000ff) p.append(hx.get_units(1)) t.append(utime.ticks_ms()) steps += 1 if steps == 10: x1 = p[-3] - p[-2] x2 = p[-1] - p[-0] if x1 - x2 < 0 or test == True: program = 0 dac.write(0) pycom.rgbled(0xFF0000) print('PROGRAM ENDED') print(t[2]-t[1]) for T,P in zip(t,p): print('{},{}\n'.format(T-t[0],P))I used utime.tick_ms for timing.
I see i used a different method to get the value.
Need to check my results with just read..Thanks!
-
@epstein actually the method read() takes less than 1 ms now, compared to 18ms before, so it is 20 times faster now. So if you see 11-12 ms, then you are timing something else too. Which method are you using for reading the value?
And no, don't worry about the HX711. It is just a few Euro. And I want to know, if my SPI idea works (50 times faster).
Edit: If you do not set the HX711 to high speed, it will provide values at 10Hz or every 100 ms. So how do you time the speed of reading a value?
-
@robert-hh Wow many thanks for thinking along with me and spoonfeeding me the piece of code. I'm really grateful.
I've tried running your version of the driver/library and it runs in about 11 - 12 ms. That's indeed an improvement. Thanks for that. The actual values I still have to calibrate/compare to see if they make sense.
I think you are right about the HX711 board. Max. speed would be 80 Hz (If you cut the pcb line to enable that speed). So that would be the bottleneck in general then.
I hope you need the HX711 board for some project of your own or else i feel guilty that you ordered one...
Again muchos kudos for the effort.
-
@epstein I did a simple test without a HX711, just tying dOUT to GND and calling read. each call of read takes about 18ms in my test. I will still try the SPI variant, but until then I made an optimized Python variant, which takes <1ms. It still could be faster (0.6ms), if you drop the disable_irq/enable_irq calls. but then it is not guaranteed, that the high pulse is always shorter than 50 µs. I ordered an HX711. Until then, I'm not sure that the code returns the proper value. The clock timing is fine. Here is the code:
from machine import Pin, enable_irq, disable_irq class HX711: def __init__(self, dout, pd_sck, gain=128): self.pSCK = Pin(pd_sck , mode=Pin.OUT) self.pOUT = Pin(dout, mode=Pin.IN, pull=Pin.PULL_DOWN) self.GAIN = 0 self.OFFSET = 0 self.SCALE = 1 self.lastVal = 0 self.allTrue = False self.set_gain(gain); def set_gain(self, gain): if gain is 128: self.GAIN = 1 elif gain is 64: self.GAIN = 3 elif gain is 32: self.GAIN = 2 self.pSCK.value(False) self.read() print('Gain set') def read(self): result = 0 # wait for the device being ready while self.pOUT() == 1: pass # shift in data for j in range(24): result <<= 1 state = disable_irq() self.pSCK(True) self.pSCK(False) enable_irq(state) result |= self.pOUT() # set channel and gain factor for next reading for i in range(self.GAIN): state = disable_irq() self.pSCK(True) self.pSCK(False) enable_irq(state) # check for all 1 if result == 0xffffff: print('all true') self.allTrue = True return self.lastVal self.allTrue = False # check sign if result > 0x7fffff: result -= 0x1000000 self.lastVal = result return result def read_average(self, times=3): sum = 0 effectiveTimes = 0 readed = 0 for i in range(times): readed = self.read() if self.allTrue == False: sum += readed effectiveTimes+=1 if effectiveTimes == 0: return 0 return sum / effectiveTimes def get_value(self, times=3): return self.read_average(times) - self.OFFSET def get_units(self, times=3): return self.get_value(times) / self.SCALE def tare(self, times=15): sum = self.read_average(times) self.set_offset(sum) def set_scale(self, scale): self.SCALE = scale def set_offset(self, offset): self.OFFSET = offset def power_down(self): self.pSCK.value(False) self.pSCK.value(True) def power_up(self): self.pSCK.value(False)Edit: I did a dry coding (w/o the HX711) of the SPI version. Calling the read() method takes 0.35 ms, the raw data capture takes ~0.12 ms. The clock timing is very nice at 1 µs pulse width.
Once I get an HX711 and I know, it returns the right result, I'll post the code.
-
@epstein Besides optimization of the code, the fastest rate the HX711 can provide samples is 80Hz, or one sample every 12.5 ms.
-
@epstein floating numbers are fast. As far as I can tell it's the bit-banging I/O that takes the time. I have to go back to the datasheet, but SPI could do that much faster.
Edit: so I looked at the data sheet. The problem is that precisely 25 to 27 clock pulses are required, which you cannot do with SPI. BUT, you could use MOSI for the clock pulse with a 010101..... pattern and shift the data in, which then of course has to be folded back, because of the extra bits.
I do not have an HX 711 here, so I cannot test that, but I could try to simulate at least the I/O.