Issue with RTC on FiPy. Unexplainable delays when used.
-
Hello.
I hope someone from Pycom will chime in here.
As topic states, i am experiencing some unexplainable delays after having synced my FiPy's RTC with a NTP-server.
I have a somewhat complex code running on a FiPy, which uses lightsleep, and then accelerometer-wakeup to wake from lightsleep, and using an Timer-Alarm firing every 10 ms to take accelerometer samples, and saving an RTC timestamp with each sample onto a file. But I was experiencing some weird delays in the timestamp values, an offset of several (sometimes in the 100's) ms now and then.
For that reason i started stripping my code down to the bare essentials. No sleep / wakeup, no accelerometer, no saving of files. Simply just using a Timer-Alarm to get timestamps from RTC every 10 ms.
If i run the following code:
import time import utime import machine from machine import Timer from network import WLAN rtc = machine.RTC() NTP_SERVER = "time.google.com" last_timestamp_id = 0 wlan = WLAN(mode=WLAN.STA) wlan.scan() wlan.connect(ssid='XXXXXXXXX', auth=(WLAN.WPA2, 'XXXXXXXX')) #insert own ssid and auth while not wlan.isconnected(): pass print(wlan.ifconfig()) rtc.ntp_sync(NTP_SERVER, update_period = 3600) #line 22 while not rtc.synced(): print('.',end='') time.sleep(1) print("RTC Syncronized!") rtc.ntp_sync(None) #line 27 def getTimeStamp(): sampleTime = rtc.now() sec = utime.mktime(sampleTime)*1000 micro = sampleTime[6] /1000 return sec + round(micro) def sample(): global last_timestamp_id timestamp_id = getTimeStamp() diff = timestamp_id - last_timestamp_id last_timestamp_id = timestamp_id if diff > 12: print(timestamp_id) print(diff) timestamp_timer = Timer.Alarm(lambda x: sample(), ms = 10 , periodic = True)The following output will be produced after running for a minute or two:
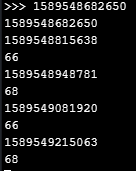
Note that the two first printouts are non-relevant (caused by last_timestamp = 0). But after about a minute or so, i start getting delays of up to 68 ms, even though all it's doing is getting timestamps and doing some minor calculations. (i chose to only print the delays, the "diff", if they are larger than 2 ms.)
Now if i comment lines 22-27 out, so there's no ntp_sync() happening, and i'm just using the epoch rtc time, i am seeing no delays at all.
I even tried a couple of variations. Shorter or longer update_periods makes no difference. Tried both with and without the ntp_sync(None) on line 27, does not make any difference. This last one surprises me, since my suspicion was that it was the update period that was doing something weird.
My firmware version:
(sysname='FiPy', nodename='FiPy', release='1.20.2.rc6', version='v1.11-01f49f7 on 2020-02-28', machine='FiPy with ESP32', lorawan='1.0.2', sigfox='1.0.1', pybytes='1.3.1')So to summarize: When using an NTP server to sync the RTC, it does create some delays that i am struggling to understand, and with more complex code, the delays naturally get longer, which certainly is unwanted behaviour.
Can someone make sense of what is causing these delays?
Thanks in advance.
/RM
-
Ok. There is a bug the way i see it. Because saving my timestamp and the operations i do with them using global variables, also produces the delays at the regular seen intervals!
With this code running:
import time import utime import machine import gc import struct from machine import Timer, RTC from network import WLAN rtc = machine.RTC() current_timestamp = None diff = None sampleTime = None sec = None micro = None last_timestamp_id = 0 def getTimeStamp(): global sampleTime global sec global micro sampleTime = rtc.now() sec = utime.mktime(sampleTime)*1000 micro = sampleTime[6] /1000 return sec + round(micro) print(rtc.now()) def sample(): global last_timestamp_id global diff global current_timestamp current_timestamp = getTimeStamp() diff = current_timestamp - last_timestamp_id last_timestamp_id = current_timestamp if diff > 12: print("Delay registered!") print(diff) print(rtc.now())Output:
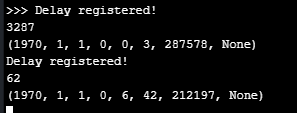
I am still seeing delays every 6 mins and 40 secs!
And if i sync with the NTP Server first, while using global variables, i am seeing the delay of 2min 13 secs too!
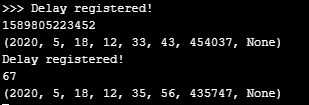
So using global variables all over does not solve the problem either! Seems to me that when using the RTC on a 10 milisecond schedule the FiPy has a bug. How it's related to the GC i am not able to tell...
-
@jcaron utime.ticks_ms() is not viable either, since i need a timestamp, not the time in ms since boot (uptime).
-
@jcaron Yes that is quite peculiar. Even though the GC methods are taxing (adding a call to gc.collect() always infers a delay when sampling timestamps with 10 ms. intervals), i started to go a little further down that path.
I modified my code, to make a call to gc.collect() every 2 minutes (see code below - the gc_diff check + a global last_gccollect variable). Doing so actually removes the delays at i was seeing at the mentioned intervals, now i am just getting a delay every 2 minutes when the call to gc.collect() happen. But at least i am then in "control" of when the delays occurs. So it seems @crumble was onto something.
So the next thing i wanted to try, was to print the result of gc.mem_free() every time we exceed the diff of 12, to be able to monitor if there is actually no memory left. But as i wrote earlier, adding this line, makes the diff value exceed 12 all the time!?! But i can add it in the first if, where i'm making sure to call GC every 2 minutes without the delays happen all the time. However this does not give me what i want, since what i wanted was to monitor memory, when the non-GC induced delays happen.
last_gccollect = 0 def sample(): global last_timestamp_id global last_gccollect timestamp_id = getTimeStamp() diff = timestamp_id - last_timestamp_id last_timestamp_id = timestamp_id gc_diff = timestamp_id - last_gccollect #print(gc.mem_free()) #Having this line here causes delays all th time! if gc_diff > 120000: print(gc.mem_free()) #Works without causing delays all the time! gc.mem_alloc() gc.collect() print("GC called!") last_gccollect = timestamp_id if diff > 12: #print(gc.mem_free()) #Having this line here causes delays all the time! print("Delay registered!") print(diff) print(rtc.now())But even though monitoring the memory the way i wanted is not possible with this setup, it would seem that the problem is memory related. Sadly i cannot garbage collect without delays, when sampling at 10 ms.
A way around it that i can come up with myself, is to store the timestamps in a global variable, which then will get updated every time i take a sample, but it will not use more memory per sample. But i would really like another solution if possible. I'll test it out and get back to you!
-
@railmonitor Interesting that in cases 2 and 3 the error interval is exactly 3 times that of case 1.
-
@railmonitor Ah sorry, I thought
utime.timereturned fractional seconds.Try
utime.ticks_msthen. Won't give you an absolute time, but for measuring intervals it should be fine. Useutime.ticks_diffto compute the difference.
-
Hi.
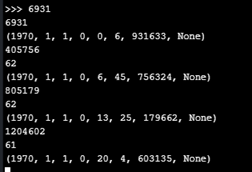
A little further testing, and i have some interesting results. I tried letting the module run a little while longer with the code from the original post, where i commented out the NTP_sync() part, so the program just uses the epoch RTC time. When syncing i was experiencing the delays every 2 minutes or so. I now tried not syncing, and letting it run for a longer time. Turns out the delays also happen without sync or init of the RTC, but at much lower intervals. I have made this table with my results:

Test 1 output:
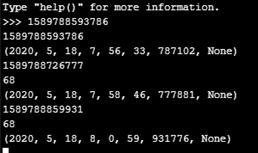
Test 2 and 3 output:
EDIT:
@jcaron the way i am testing for the delays (in ms) makes utime.time which only operates with seconds non-relevant to what i need. My eventual program must sample every 10 ms. and i need a individual timestamp for each sample.
-
@railmonitor don’t think it would change much (and I haven’t looked at the source to check the implementation), but could you try replacing the calls to
RTC.now,mktime, etc. with a call toutime.time?
-
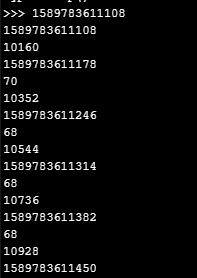
@crumble I tried checking the GC, adding a print every time my diff exceeded 12, strange thing is, that that made my diff value exceede 12, even though it should only be called every time diff exceeds 12!? Unless calling the GC methods takes a lot of resources it makes no sense to me, maybe there is something else for the Pycom folks to look into here. However i don't think it's the source of my problem:
def sample(): global last_timestamp_id timestamp_id = getTimeStamp() diff = timestamp_id - last_timestamp_id last_timestamp_id = timestamp_id if diff > 12: print(timestamp_id) print(diff) print(gc.mem_alloc()) #adding this line gives weird behaviour!Output:
Adding a call to gc.collect() in my sample method:
def sample(): global last_timestamp_id timestamp_id = getTimeStamp() diff = timestamp_id - last_timestamp_id last_timestamp_id = timestamp_id gc.collect() #GC! if diff > 12: print(timestamp_id) print(diff)Also makes the diff value exceede 12 constantly (but with about half of the delay in ms.):
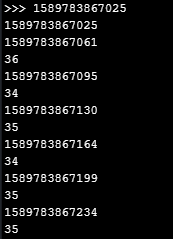
@robert-hh
No, and just to be sure i tried running my code while making sure to disable the WiFi connection just after the call to ntp_sync(), but it made no difference. And seeing as how i did also tried calling rtc.ntp_sync(None), to disable the re-sync / update_period i believe there is a bug!Tried a NTP server from pool.ntp.org, but changing server didn't solve anything.
I then found this post, it is not really relevant to my problem, but it shows how to connect manually using socket to an NTP server and syncing time, without actually calling ntp_sync():
https://forum.pycom.io/topic/4187/question-about-expected-ntp_sync-behavior/3
So i tried his example of connecting to NTP server and syncing (which works), but i am still seeing the delays.
UPDATE: I tried to run the same code, but using rtc.init(2020, 5, 18) instead of ntp_sync(), and i still get the delay. So the delays are present whenever RTC is set, either by sync or init or by socket. The delays are not present when simply just using the RTC without setting it first (but we don't want epoch time).
Can someone else confirm this is a bug? Would be great if someone else with a FiPy could test, and how do i go about reporting it?
-
@railmonitor Is there any network activity when these delays happen? Maybe the time is re-synched with ntp, vwnw if the period is set to 3600. If yes, then there is a bug in this module.
-
Check the garbage collector. If you are using floats, each operator use generates one or more objects. The will be cleaned up when there is no more free RAM. This shall not need hundreds of ms, but may be the root of following delays.